Metode-Metode Information Retrieval
Information Retrieval memiliki beberapa metode dalam mengambil data dan informasi antara lain inverted index, Boolean retrieval, tokenization, stemming and lemmatization, dictionaries, wildcard queries, dan vector space model.
Inverted Index
Inverted index adalah sebuah struktur data index yang dibangun untuk memudahkan query pencarian yang memotong tiap kata (term) yang berbeda dari suatu daftar term dokumen. Inverted index memiliki tujuan untuk meningkatkan kecepatan dan efisiensi dalam melakukan pencarian pada sekumpulan dokumen dan menemukan dokumen-dokumen yang mengandung query user (CatenaCraig, Macdonald, & Ounis, 2014).
Information need merupakan topik dimana user ingin tahu lebih jauh, sedangkan query merupakan cara user berkomunikasi dengan komputer untuk memperoleh informasi yang diinginkan. Oleh karena itu, agar hasil yang diperoleh memiliki hasil yang baik dilakukan pengujian pada sistem IR. Pengujian efektifitas system IR menggunakan dua acara yaitu precision dan recall. Precision adalah tingkat ketepatan antara informasi yang diminta oleh pengguna dengan jawaban yang diberikan oleh sistem. Sedangkan recall adalah tingkat keberhasilan sistem dalam menemukan kembali sebuah informasi (Bucher, Clarke, & Cormack, 2010). Adapun langkah-langkah yang dilakukan pada inverted index antara lain:
- Menentukan dokumen yang akan diindeks;
- Melakukan Tokenize teks, tiap dokumen menjadi token;
- Membuat dictionary dan posting list;
- Melakukan preprocessing linguistic dan menghasilkan token;
- Mengindeks dokumen dimana tiap term terjadi dengan membuat inverted index.
Setiap dokumen memiliki serial number unik untuk dikenal sebagai identitas dokumen. Pada proses konstruksi indeks, kit adapt memberkan nilai trigger untuk tiap dokumen baru yang ditemukan. Selanjutnya adalah mengurutkan sehingga term alfabetis. Dictionary merekam statiskik seperti jumlah dokumen yang berisi tiap term yang berguna pada search engine pada saat query. Contoh:
Query: Brutus dan Calpurnia.
Ilustrasi:
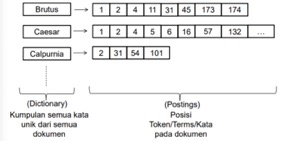 Gambar 1.1. Ilustrasi Inverted Index. (Sumber: (CatenaCraig et al., 2014))
Gambar 1.1. Ilustrasi Inverted Index. (Sumber: (CatenaCraig et al., 2014))
- Cari Brutus pada dictionary;
- Ambil posting;
- Cari Calpurnia pada dictionary;
- Ambil posting;
- Intersect 2 posting list
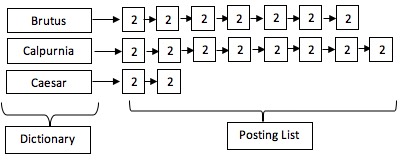
Gambar 1.2. Representasi Inverted Index. (Sumber: (CatenaCraig et al., 2014))
Intersect posting list untuk dapat mencari dokumen berisi kedua term atau disebut merging posting list. Kita dapat menggunakan algoritma merge.
Boolean Retrieval
Boolean Retrieval merupakan proses pencarian informasi dari query yang menggunakan ekspresi Boolean (Bucher et al., 2010). Dengan ekspresi boolean dengan menggunakan operator logika AND, OR dan NOT. Dalam menentukan hasil perhitungannya hanya berupa nilai binary (1 atau 0). Hasil boolean retrieval yang ada hanya dokumen relevan atau tidak sama sekali. Sehingga keunggulan dari boolean retrieval tidak menghasilkan dokumen yang sama.
Dalam pengerjaan operator boolean (AND, NOT, OR) ada urutan pengerjaannya (operator precedence). Dalam implementasinya akan memprioritaskan yang berada dalam kurung (), baru selanjutnya NOT, AND, dan OR. Boolean retrival melakukan perbaikan karena datanya terlalu besar bila tersimpan dalam komputer, seperti ini kita perlu memenuhi peraturannya diantaranya kecepatan dalam pemrosesan dokumen yang sangat banyak, fleksibilitas dan perangkingan. Berikut adalah penjelasan dari operator pada model boolean retrieval antara lain:
- Logical AND
Logical AND memperbolehkan penelusur untuk menggunakan pernyataan query ke dalam suatu lebih konsep sehingga hasil penelusuran menjadi lebih terbatas. Formula pernyataan sederhana A AND B. Contoh untuk menelusur marketing and library, kita memformulasikan pernyataan dengan marketing AND library. Dengan query tersebut maka kita akan menemukan dokumen yang mengandung unsur marketing dan perpustakaan saja, dan tidak mendapatkan dokumen yang hanya mengandung unsur marketing atau perpustakaan saja.
- Logical OR
Logical OR memperbolehkan untuk secara spesifik menggunakan alternative term (atau konsep) yang mengindikasikan dua konsep sesuai dengan tujuan penelusuran menjadi lebih luas, karena adanya alternative dalam pernyataan query. Formulasi pernyataan sederhana A OR B. Contoh marketing OR library. Dengan query tersebut maka kita akan mendapatkan dokumen yang mengandung unsur marketing saja, perpustakaan saja atau yang mengandung unsur marketing dan perpustakaan.
- Logical NOT
Logical NOT dapat mengecualikan item-item dari seperangkat term penelusur. Pernyataan formulasi sederhana A NOT B, contoh markeing NOT library. Ini artinya kita hanya menginginkan dokumen yang unsur marketing di dalamnya tidak ada unsur perpustakaannya.
- Kombinasi Logical AND, OR, NOT
Kombinasi logical AND, OR, NOT dapat mengkombinasikan satu pernyataan ke dalam penelusur yang kompleks. Contoh marketing AND library OR information centre NOT profit organization. Artinya kita ingin mendapatkan dokumen yang mengandung unsur marketing dan perpustakaan tanpa unsur pusat informasi bukan untuk organisasi non profit.
Di dalam struktur data, Boolean merupakan sebuah tipe data yang bernilai “True” atau “False” (benar atau salah). Sehingga didalam IR, logika boolean berarti bahwa data yang di crawler sesuai atau tidak antara variable – variablenya. Kelebihan boolean retrieval yaitu mudah untuk di implementasikan dan konsep yang terstruktur. Kekurangan boolean retrieval yaitu pencocokan yang tepat dapat mengambil dokumen terlalu sedikit atau terlalu banyak, sulit untuk pengindeksan, beberapa dokumen yang lebih penting dari pada yang lain kadang berada dibawah dokumen yang tidak penting, sulit untuk menerjemahkan query ke dalam ekspresi boolean, semua istilah sama-sama berbobot, lebih seperti pengambilan data dari pencarian informasi, struktur data dan algoritmanya.
Dilihat dari sudut pandang matematika atau sudut pandang praktis, boolean retrieval adalah logika yang paling mudah. Namun secara logika dan struktur data tidak semudah hal yang diutarakan diatas. Algoritma boolean retrieval diantaranya adalah Hash Table, Steeming dan lain lain
Tokenization
Tokenization adalah metode pemecah teks menjadi token-token yang berurutan. Proses tokenization primitif biasanya hanya memecah teks dengan whitespace sebagai pembagi, lalu mengubahnya menjadi huruf kecil supaya seragam. Contoh:
Teks: “Ini ibu Budi.”
Pemecahan teks: “ini”, “ibu”, “budi.”
Tokenisasi secara garis besar memecah sekumpulan karakter dalam suatu teks ke dalam satuan kata, bagaimana membedakan karakter-karakter tertentu yang dapat diperlakukan sebagai pemisah kata atau bukan. Sebagai contoh karakter whitespace, seperti enter, tabulasi, spasi dianggap sebagai pemisah kata. Namun untuk karakter petik tunggal (‘), titik (.), semikolon (;), titk dua (:) atau lainnya, dapat memiliki peran yang cukup banyak sebagai pemisah kata.
Stemming and Lemmatization
Stemming adalah proses untuk mendapatkan kata dasar dengan cara menghapus imbuhan kata. Proses stem adalah bagian dari pra-pemrosesan dokumen teks dalam pencarian informasi. Stemming merupakan sebuah proses yang bertujuan untuk mereduksi jumlah variasi dalam representasi dari sebuah kata (Kowalski, 2011). Resiko dari proses stemming adalah hilangnya informasi dari kata yang di-stem. Hal ini menghasilkan menurunnya akurasi atau presisi. Sedangkan untuk keuntungannya adalah, proses stemming bisa meningkatkan kemampuan untuk melakukan recall.
Tujuan dari stemming adalah untuk meningkatkan akurasi pencarian teks (D. Sharma, 2012). untuk meningkatkan performace dan mengurangi penggunakan resource dari sistem dengan mengurangi jumlah unique word yang harus diakomodasikan oleh sistem. Stemming juga diperlukan dalam mengompresi algoritma teks (Sinaga, Adiwijaya, & Nugroho, 2015). Jadi, secara umum, algoritma stemming mengerjakan transformasi dari sebuah kata menjadi sebuah standar representasi morfologi (yang dikenal sebagai stem).
Dalam stemming bahasa Inggris, algoritma Porter stemming adalah algoritma yang lebih sederhana dari algoritma stemming sebelumnya dari stemmer tipe Lovin. Algoritma Porter berkurang kompleksitas aturan dalam penghapusan suffix. Oleh karena itu, algoritma ini menjadi standar untuk stemmer dan menyediakan bahasa Inggris model untuk pemrosesan bahasa lain (Willett, 2006).
Dalam stemming Bahasa Indonesia, ada beberapa algoritma stemming Bahasa Indonesia antara lain algoritma Nazied dan Andriani, algoritma dari Arifin dan Setiono, algoritma Vega, algoritma William, dan Tahaghoghi, dan algoritma Arifin, Mahendra, Ciptaningtyas.
Algoritma Nazief dan Adriani menggunakan confixstripping pendekatan dengan aturan dasar [[[DP +] DP +] DP +] kata dasar [[+ DS] [+ PP] [+ P]], Vega algoritma menggunakan iterasi untuk menentukan dan menghilangkan imbuhan dari sebuah kata. Algoritma dari Arifin dan Setiono menghapus hingga dua awalan dan hingga tiga sufiks. Serupa untuk Vega, algoritma ini menggunakan iterasi dalam prosesnya. Asia, William, dan Tahaghoghi telah memperbaiki proses confixstripping pendekatan dari Nazief dan Adriani. Sementara itu Arifin, Mahendra, Ciptaningtyas juga meningkatkan konfiksasi pendekatan (Adriani, Asian, Nazief, & et al., 2007)(Asian, Williams, & Tahaghoghi, 2005)(Arifin, Mahendra, & Ciptaningtyas, 2009). Pendekatan kami berfokus pada imbuhan penghapusan dengan klasifikasi afiks fleksibilitas. Penghapusan imbuhan adalah jenis algoritma stemming (W. B. Frakes, 2003). Contoh : “comput” adalah stem dari “computable, computability, computation, computational, computed, computing, compute, computerize” (Suhartono, 2013).
Lemmatization adalah proses menemukan bentuk dasar dari sebuah kata (Ingason, Helgadóttir, Loftsson, & Rögnvaldsson, 2008). Lemmatization adalah proses normalisasi pada teks/kata dengan berdasarkan pada bentuk dasar yang merupakan bentuk lemma-nya. Normalisasi adalah mengidentifikasikan dan menghapus prefiks serta suffiks dari sebuah kata. Lemma adalah bentuk dasar dari sebuah kata yang memiliki arti tertentu berdasar pada kamus. Contoh:
Input: “The boy’s cars are different colors”
Transformation: am, is, are à be
Transformation: car, cars, car’s, cars’ à car
Hasil: “The boy car be differ color”
Dictionaries
Dua kelas utama struktur data: hash dan tree. Kriteria untuk kapan menggunakan hash vs. tree yaitu apakah ada jumlah syarat yang tetap atau apakah akan terus bertambah?; Apa frekuensi relatif dengan berbagai tombol tersebut akan diakses? Berapa banyak istilah yang mungkin kita miliki?. Hash digunakan untuk setiap istilah kosakata digabungkan menjadi bilangan bulat, mencoba menghindari tabrakan. Pada waktu permintaan, lakukan hal berikut: istilah permintaan hash, atasi tabrakan, cari entri dalam array lebar tetap. Keuntungannya pencarian cepat (lebih cepat daripada di search tree) dan waktu pencarian konstan. Kekurangan hash yaitu tidak ada cara untuk menemukan varian minor (resume vs. resume), tidak punya pencarian awalan (semua istilah dimulai dengan automat), perlu mengulang semuanya secara berkala jika vocabulary kata tetap ada pertumbuhan.
Search tree mengizinkan kita untuk mencari seluruh vocabulary terms dimulai dengan otomatis dimana search tree terbaik yaitu binary tree yang nod internal memiliki dua anak.
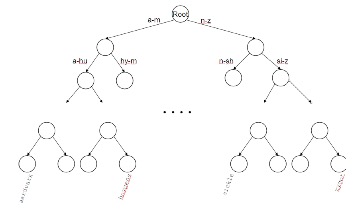 Gambar 1.3. Binary Tree. (Sumber:(Budiharto, 2016)).
Gambar 1.3. Binary Tree. (Sumber:(Budiharto, 2016)).
Binary tree merupakan struktur tree paling sederhana dan efisien untuk melakukan pencarian. Keuntungan dari binary tree adalah dapat memecahkan masalah awalan (istilah dimulai dengan automat). Kekurangan dari binary tree adalah lebih lambat: O (logM) dalam balance tree (M adalah ukuran kosakata), menyeimbangkan kembali binary tree itu mahal.
Wilcard Queries
Wilcard Queries digunakan dalam salah satu situasi berikut: (1) user tidak yakin akan ejaan istilah query, missal: Sydney vs Sidney, yang mengarah ke wildcard query S * dney); (2) user mengetahui beberapa varian ejaan istilah dan mencari dokumen yang berisi salah satu varian (missal: Warna vs. warna); (3) user mencari dokumen yang berisi varian istilah yang akan ditangkap dengan proses stemming, tetapi tidak yakin apakah mesin pencari melakukan stemming (missal: Peradilan vs peradilan, yang mengarah ke permintaan wildcard judicia *); (4) user tidak yakin dengan terjemahan kata atau frasa asing yang benar (missal: Query Universit * Stuttgart) (“Wilcard Query,” 2008).
Query seperti mon * dikenal sebagai wildcard query tertinggal, karena simbol * hanya muncul satu kali, di akhir string pencarian. Pohon pencarian pada kamus adalah cara yang nyaman untuk menangani permintaan trailing wildcard: kita berjalan di pohon mengikuti simbol m, o dan n pada gilirannya, pada titik mana kita dapat menghitung satu set $ W $ dari istilah dalam kamus dengan awalan mon. Akhirnya, kami menggunakan $ vert W vert $ lookup pada indeks terbalik standar untuk mengambil semua dokumen yang mengandung istilah apa pun dalam $ W $.
Tapi bagaimana dengan wildcard queries di mana simbol * tidak dibatasi berada di akhir string pencarian?
Sebelum menangani kasus umum ini, kami menyebutkan sedikit generalisasi dari permintaan wildcard tertinggal. Pertama, pertimbangkan untuk memimpin wildcard query, atau kueri dari form * mon. Pertimbangkan reverse B-tree pada kamus – di mana setiap jalur root-to-leaf dari B-tree sesuai dengan istilah dalam kamus yang ditulis mundur: dengan demikian, istilah lemon akan, dalam B-tree, diwakili oleh path root-nomel. Berjalan menyusuri B-tree terbalik kemudian menyebutkan semua istilah $ R $ dalam kosakata dengan awalan yang diberikan. Bahkan, menggunakan B-tree reguler bersama dengan reverse B-tree terbalik, kita dapat menangani kasus yang lebih umum: wildcard queries di mana ada simbol * tunggal, seperti se * mon. Untuk melakukan ini, kita menggunakan B-tree reguler untuk menyebutkan set $ W $ istilah kamus yang dimulai dengan awalan se, kemudian reverse B-tree untuk menghitung set $ R $ dari istilah yang diakhiri dengan akhiran mon. Selanjutnya, kita ambil persimpangan $ W cap R $ dari dua set ini, untuk sampai pada kumpulan istilah yang dimulai dengan awalan se dan diakhiri dengan akhiran mon. Akhirnya, kami menggunakan indeks terbalik standar untuk mengambil semua dokumen yang mengandung istilah apa pun di persimpangan ini. Dengan demikian, kita dapat menangani wildcard query yang berisi simbol * tunggal menggunakan dua B-tree, B-tree normal dan reverse B-tree.
Vector Space Model
Vector space model (VSM) adalah teknik dasar dalam perolehan informasi yang dapat digunakan untuk penilaian relevansi dokumen terhadap kata kunci pencarian (query) pada mesin pencari, klasifikasi dokumen, dan pengelompokan dokumen (Adriani, M., Asian, J., Nazief, B., & et al.,2007). Vector space model merupakan representasi kumpulan dokumen sebagai vektor dalam sebuah ruang vector (Akerkar, R., 2005). Dalam Vector Space Model, koleksi dokumen direpresentasikan sebagai sebuah matrik term-document (matrik term-frequency). Setiap sel dalam matrik bersesuaian dengan bobot yang diberikan dari suatu term dalam dokmen yang ditentukan. Nilai nol berarti bahwa term tersebut tidak hadir dalam dokumen .
Melalui vector space model dan TF weighting maka akan didapatkan representasi nilai numerik dokummen sehingga kemudian dapat dihitung kedekatan antar dokumen. Semakin dekat dua vektor di dalam suatu VSM, maka semakin mirip dua dokumen yang diwakili vektor tersebut. Fungsi untuk mengukur kemiripan (similarity measure) yang dapat digunakan untuk model ini terdiri dari :
- Cosine distance / cosine similarity
- Inner similarity
- Dice similarity
- Jaccard similarity
Salah satu ukuran kemiripan teks yang popular adalah cosine similarity. Ukuran ini menghitung nilai cosinus sudut antara dua vektor. Jika terdapat dua vektor dokumen d dan query q, serta t term diekstrak dari koleksi dokumen maka nilai cosinus antara d dan q didefinisikan sebagai berikut :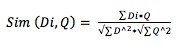
Referensi:
- Adriani, M., Asian, J., Nazief, B., & et al. (2007). Stemming Indonesian: A Confix-Stripping Approach. ACM Transactions on Asian Language Information Processing, 6, 1–33.
- Akerkar, R. (2005). Introduction to Artificial Intelligence. Prentice Hall India.
- Arifin, A. Z., Mahendra, I. P. A. K., & Ciptaningtyas, H. T. (2009). Enhanced Confix Stripping Stemmer and Ants Algorithm for Classifying News Document in Indonesian Language. International Conference on Information & Communication Technology and Systems, 149–158.
- Asian, J., Williams, H., & Tahaghoghi, S. (2005). Stemming Indonesian. Conferences in Research and Practice in Information Technology Series, 38, 307–314.
- Bucher, S., Clarke, C. L. ., & Cormack, G. V. (2010). Information Retrieval – Implementing and Evaluation Search Engines. MIT Press.
- CatenaCraig, M., Macdonald, & Ounis, I. (2014). On Inverted Index Compression for Search Engine Efficiency. European Conference on Information Retrieval ECIR 2014: Advances in Information Retrieval, 359–371.
- Sharma, M. C. (2012). Stemming Algorithms: a Comparative Study and Their Analysis. International Journal of Applied Information Systems (IJAIS), 4(3), 7–12.
- Kowalski, M. (2011). Information Retrieval Architecture and Algorithms. New York: Springer.
- Sinaga, A., Adiwijaya, & Nugroho, H. (2015). Development of Word-Based Text Compression Algorithm for Indonesian Language Document. International Conference on Information and Communication Technology (ICOICT), 3, 450–454.
- B. Frakes, C. J. F. (2003). Strength and Similarity of Affix Removal Stemming Algorithms. ACM SIGIR Forum, 37, 26–30.
- Wilcard Query. (2008). Retrieved April 6, 2020, from https://nlp.stanford.edu/IR-book/html/htmledition/wildcard-queries-1.html
- Willett, P. (2006). The Porter Stemming Algorithm: Then and Now. Emerald Insight, 40(3), 219–223
Penulis: Emny Harna Yossy, S.Kom., M.T.I.